萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
还在为图像加载犯愁吗?
最新的好消息是,谷歌团队采用了一种GANs与基于神经网络的压缩算法相结合的图像压缩方式HiFiC,在码率高度压缩的情况下,仍能对图像高保真还原。
GAN(Generative Adversarial Networks,生成式对抗网络)顾名思义,系统让两个神经网络相互「磨炼」,一个神经网络负责生成接近真实的数据,另一个神经网络负责区分真实数据与生成的数据。
简单来说,就是一个神经网络「造假」,另一个神经网络「打假」,而当系统达到平衡时,生成的数据看起来便会非常接近真实数据,达到「以假乱真」的效果。
下面是这种算法展现出来的图像与JPG格式图像的对比。
可见,在图像大小接近的情况下(HiFiC大小74kB,JPG图像大小78kB),算法所展现出来的图像压缩效果要好得多。


但看惯了高清视频的网友们,面对突如其来的「模糊打击」自然怨声载道。
用一位网友的话来说,如果视频行业也能被应用类似的技术,相信Netflix和油管会特别高兴,毕竟这种高清低码率的图像复原实在太诱惑。
事实上,在了解HiFiC算法的原理后,会发现它的确不难实现。
接近原图的图像重构算法
此前,相关研究已有采用神经网络进行图像压缩的算法,而随着近年来生成式对抗网络兴起,采用GANs生成以假乱真图像的算法也不在少数。
如果能有办法将二者结合,图像压缩的效果是不是会更好、更接近于人类的感知?
这次图像压缩的模型便是基于二者的特性设计,在基于神经网络的压缩图像算法基础上,采用GANs进一步让生成的图片更接近于人类视觉,在图像大小和视觉感知间达到一个平衡。
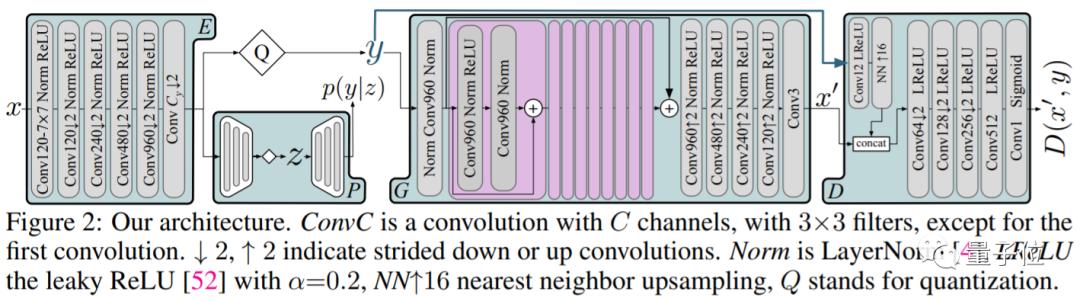
GANs运作的核心思想在于,需要让架构中的生成器G通过某种方法,「欺骗」判别器D判定样本为真。
而概率模型P,则是达成这步操作的条件。
然后,将E、G、P参数化为卷积神经网络,这样就可以通过率失真优化的条件,对这些网络进行共同训练。
同时,研究者也对已有的几种GANs算法架构进行了微调,使其更适于HiFiC架构。
研究发现,将GANs与深度学习相结合的HiFiC算法取得了意想不到的效果。
模型评估
下图是采用目前几种主流图像质量评估标准,对几种前沿的图像压缩算法与HiFiC算法进行比较的结果。
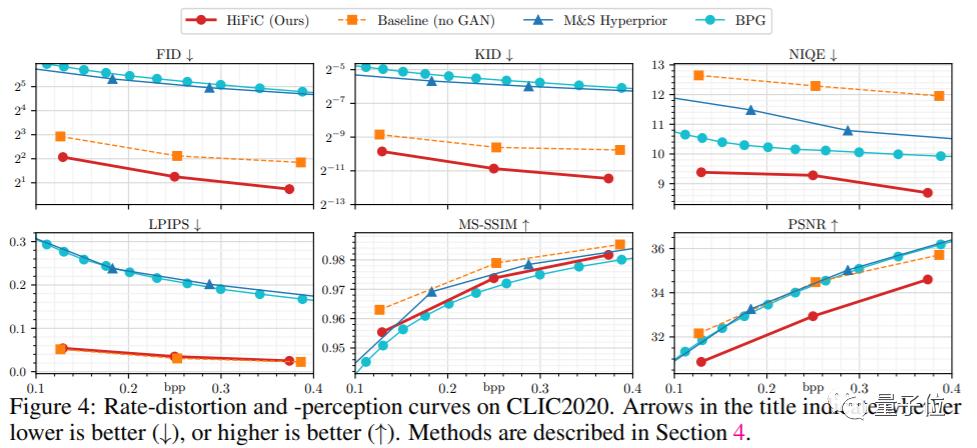
为了更好地对比,结果分别采用了HiFiC算法(图中红点连线)、不带GANs的对比算法(图中橙方连线)、目前较为前沿的M&S算法(图中蓝方连线)和BPG算法(图中蓝点连线)。
从结果来看,HiFiC算法在FID、KID、NIQE、LPIPS几种评估标准均为最优,而在MS-SSIM和PSNR标准中表现一般。
由评估标准间的差异可见,各项图像质量标准不一定是判断压缩技术的最好办法。
用户评测对比
毕竟,图像是用来看的,最终的判断权还得交回用户手里。
图像究竟是否「清晰」,某种程度上得通过人眼的判断来决定。
出于这个考虑,团队采取了调研模式,让一部分志愿者参与算法的比较。
他们先展示一张测试图片的随机裁切图样,当志愿者对其中某张裁切图样感兴趣时,便用这一部分来进行所有算法的对比。
志愿者将原图与经过算法处理后的图像对比后,选出他们认为「视觉上」更接近于原图的压缩算法。
在所有算法经过选取后,将会出现一个排名,以衡量HiFiC的实际效果。(其中,HiFiC的角标Hi、Mi和Lo分别为设置由高至低3种不同码率阈值时的算法)
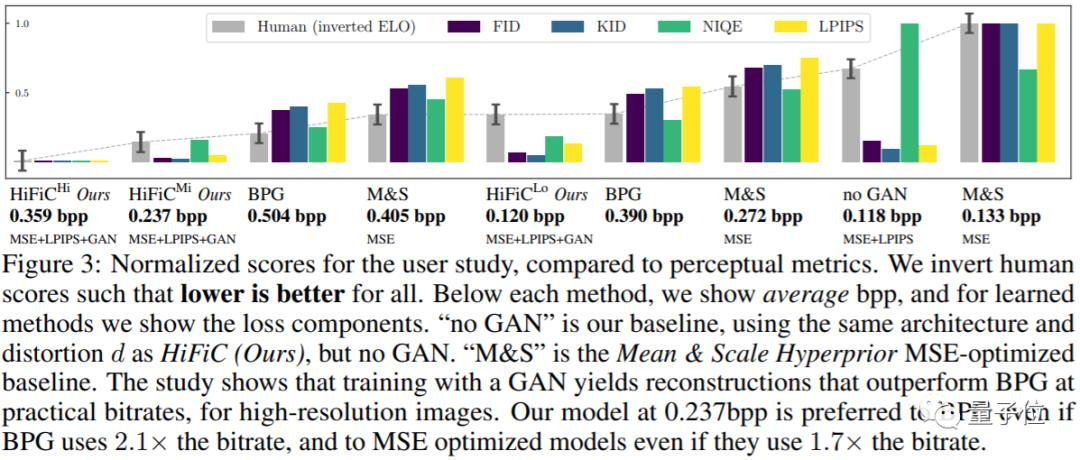
即使压缩效果达到了0.120bpp,也比0.390bpp的BPG算法更好。
这项研究再次推动了图像压缩技术的发展,正如网友所说,随着图像压缩技术的发展,在线看4k电影也许真能实现。
作者介绍

这篇论文的主要工作由Fabian Mentzer在谷歌研习期间完成,其余三位作者均来自谷歌团队。
目前有关这个项目的源代码和训练好的模型也即将放出,小伙伴们可以戳下方传送门查看最新进展。
